|
AI researcher at Google DeepMind (Gemini), specializing in multi-modal learning. Postdoc at Meta AI (SAM 2), PhD from Inria, MSc from Toulouse University, MSc from Icam. Former mechanical engineer with 6 years of experience in industrial automation.
|

|
|
|

|
|
|
|
|
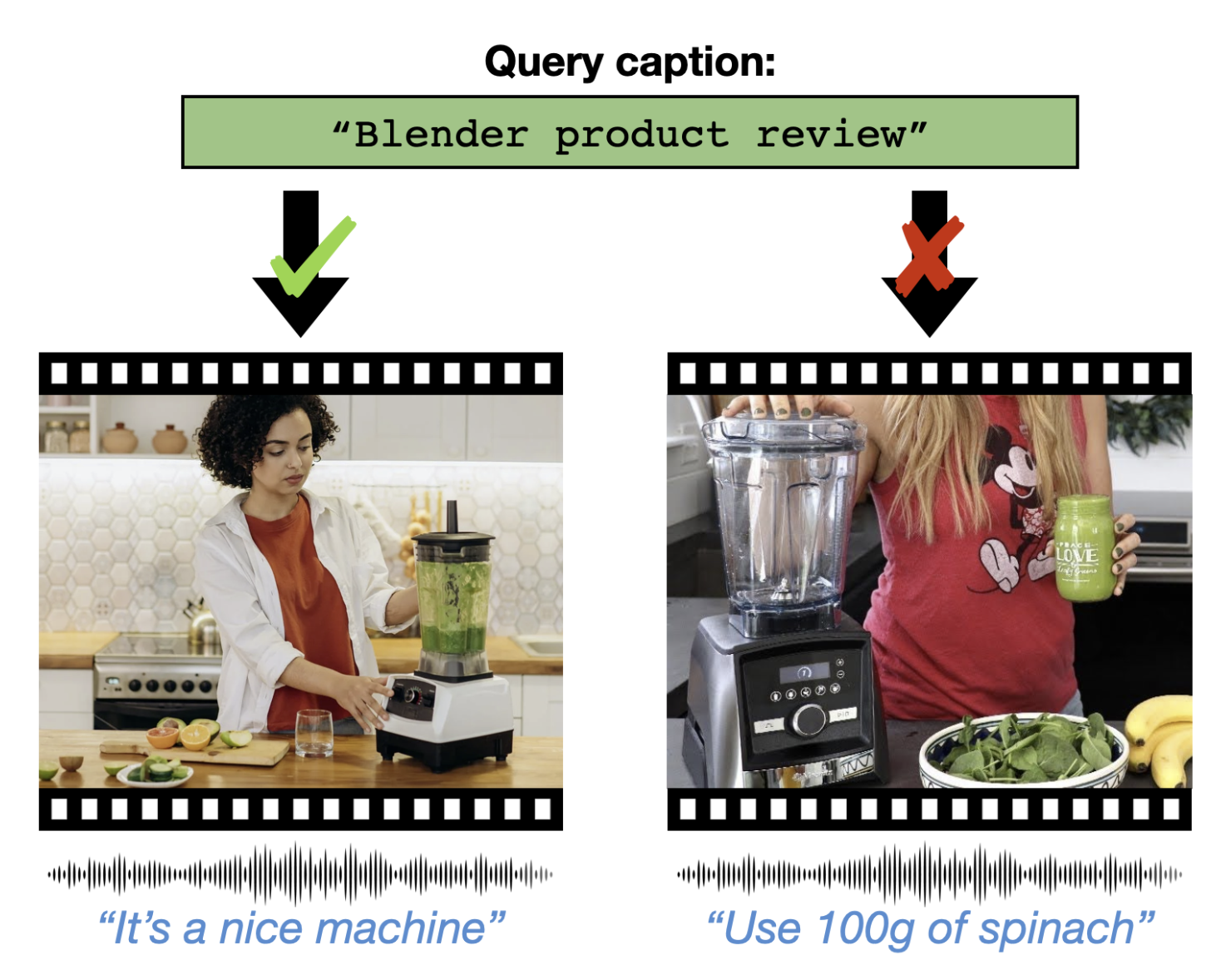
|
|
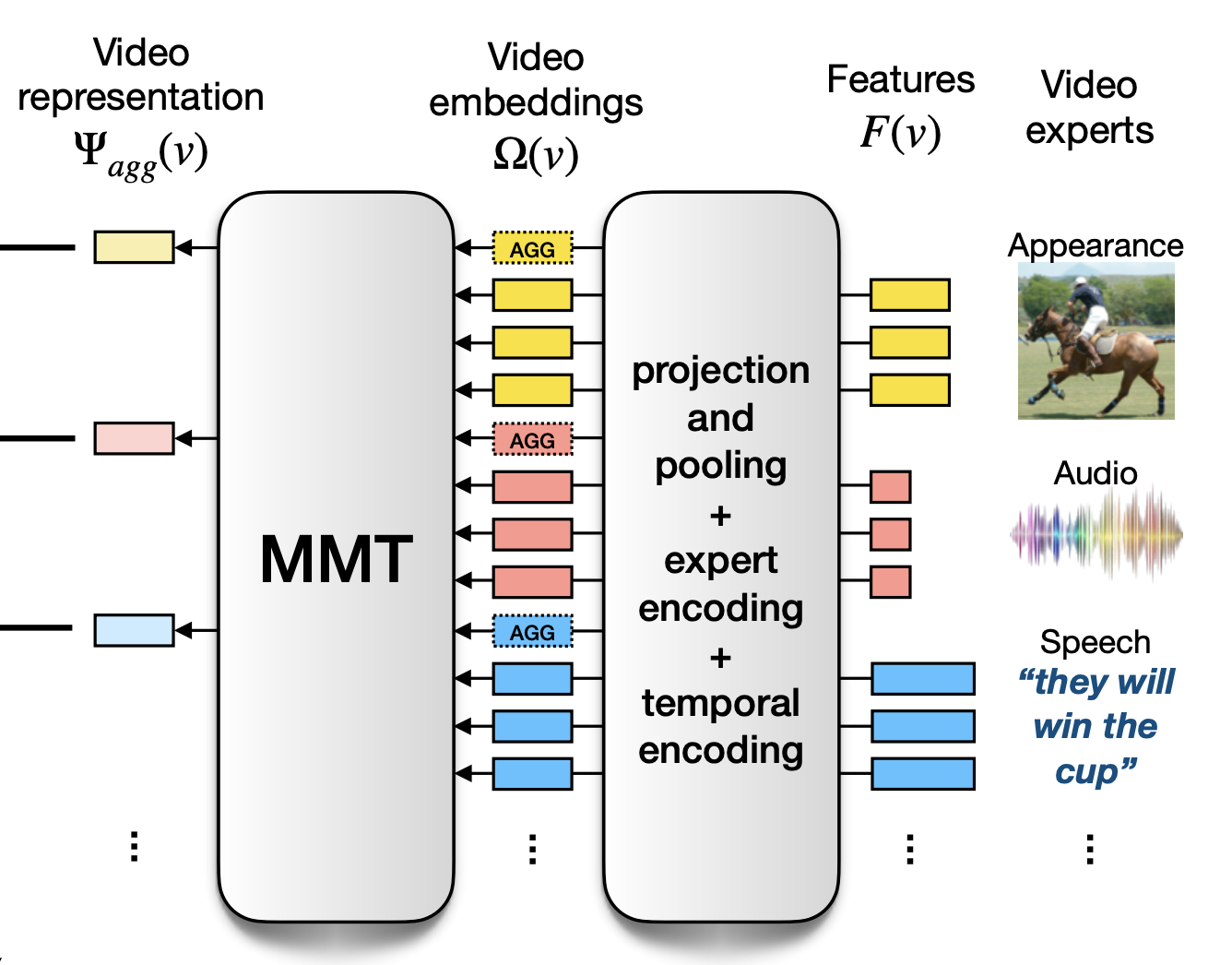
|
|
|
|
|
|---|---|
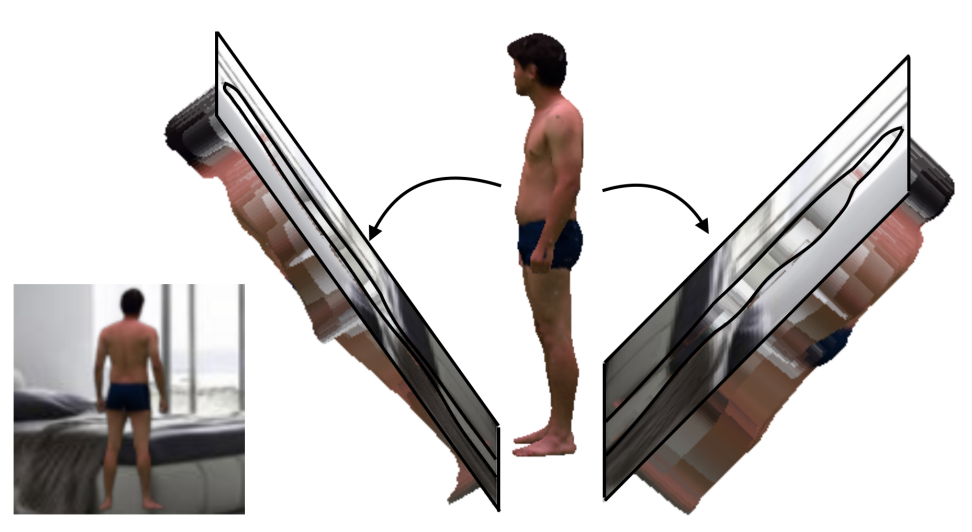
|
|
|
Credits to Jon Barron for the template. |